






Published: by Lucas Rolff
Pulse Week 13: AVIF Effort Settings and Photon Optimizer Migration
Testing AVIF effort settings
Over the course of a couple of weeks, we've been experimenting with various "CPU effort" settings for optimizing AVIF images within Photon Optimizer.
AVIF uses a "CPU effort" setting during image compression, ranging from 0 to 9. This setting effectively determines how much time the AVIF encoder spends trying to achieve better compression for a given image; more time spent can potentially lead to greater file size reductions.
However, it's important to note that increasing the effort doesn't always yield significant gains, so finding the right balance is crucial.
In this context, an effort of 0 is the slowest (most effort), and 9 is the fastest (least effort). For some time, we've used an effort of 8 because it produces slightly smaller images compared to WebP while remaining relatively fast.
We wanted to investigate how different effort settings impact encoding performance for images that aren't served from our Varnish cache (a MISS), and whether there are any tangible benefits in terms of file size.
We quickly discovered that changing the CPU effort from 8 to 7 (slightly increasing the effort) resulted in a 30% increase in our 95th percentile processing time for image optimization, which is a considerable increase. However, this only yielded approximately 1.4% in additional file size savings across roughly 550,000 unique images processed by the platform.
While individual images might see more substantial savings with increased effort, the overall dataset suggests that increasing the CPU effort setting is not worthwhile.
As more images are processed through our Photon Optimizer service, we'll continue to conduct these tests periodically, as the overall image characteristics may change over time.
We're also exploring additional techniques to further reduce the file sizes of both WebP and AVIF formats, aiming for even greater savings for end-users.
Note: Some tools, such as Sharp, reverse the effort scale, with 0 being the fastest and 9 the slowest.
Migration of Photon Optimizer backend
In recent weeks, while working on the Photon Optimizer service, we also decided to explore optimizing the underlying hardware.
Initially, the service relied on Apache Traffic Server for caching in several locations. To keep things simple, Apache Traffic Server communicated with a load balancer IP, which fronted several Photon Optimizer workers.
These servers were Hetzner Cloud CPX instances, which are shared AMD instances.
However, a recent change involving the redesign of our caching boxes to use a combination of Varnish and HAProxy allowed us to move additional failover logic to each cache box. By having HAProxy monitor multiple upstreams and assign different weights and priorities based on location, we could effectively eliminate the need for load-balanced environments. This allowed us to utilize multiple servers across various providers in different countries if desired.
Consequently, we began testing various hardware configurations, primarily to assess the performance of converting a large PNG image to AVIF, as AVIF conversion is significantly more resource-intensive than WebP conversion.
We evaluated the hardware we had available and conducted basic benchmarks by sending two concurrent requests continuously to obtain a reliable average.
The converted image was stored locally on each server in a RAM disk to eliminate network and disk I/O as factors in the benchmark. Tests were conducted over the local network to minimize latency between the test client and the worker.
The results below demonstrate that encoding our test image varies considerably depending on the underlying hardware. We also compared a dedicated server with an AMD Ryzen 7900 to a VM provider offering VMs using AMD Ryzen 7900 to determine the impact of virtualization on performance. While dedicated solutions offer some advantages, they also come at a significantly higher cost.
It's worth noting that the Genoa-based VM was located on a hypervisor with considerable utilization. It's well-known that high-core-count Genoa processors experience performance degradation when exceeding approximately 50% CPU load due to CPU power limits.
Dedicated AMD Ryzen 7900: Time per request: 411.743 [ms] (mean) VM based on AMD Ryzen 7900 (Borrowed from our friends at SpeedyPage): Time per request: 488.043 [ms] (mean) VM based on AMD Ryzen 7950X (Borrowed from our friends at SpeedyPage): Time per request: 490.261 [ms] (mean) VM based on AMD Genoa: Time per request: 734.398 [ms] (mean) Hetzner (CPX): Time per request: 835.570 [ms] (mean) VM based on AMD EPYC 7402: Time per request: 1057.406 [ms] (mean) Dedicated Intel Xeon 2698v4: Time per request: 1113.757 [ms] (mean) OVH VPS (EPYC, unknown generation): Time per request: 1172.953 [ms] (mean) Leaseweb VPS (EPYC, 7003 series): Time per request: 1352.599 [ms] (mean)
Our findings indicate that AMD Ryzens are generally well-suited for services like this due to their high clock speeds and strong IPC (instructions per clock) performance.
On March 15, we transitioned to a Ryzen 7900-based backend based on the favorable results from our benchmarks.
Based on a week's worth of data on processing times, we observed a 45% reduction in the 95th percentile processing time after switching the backend servers.
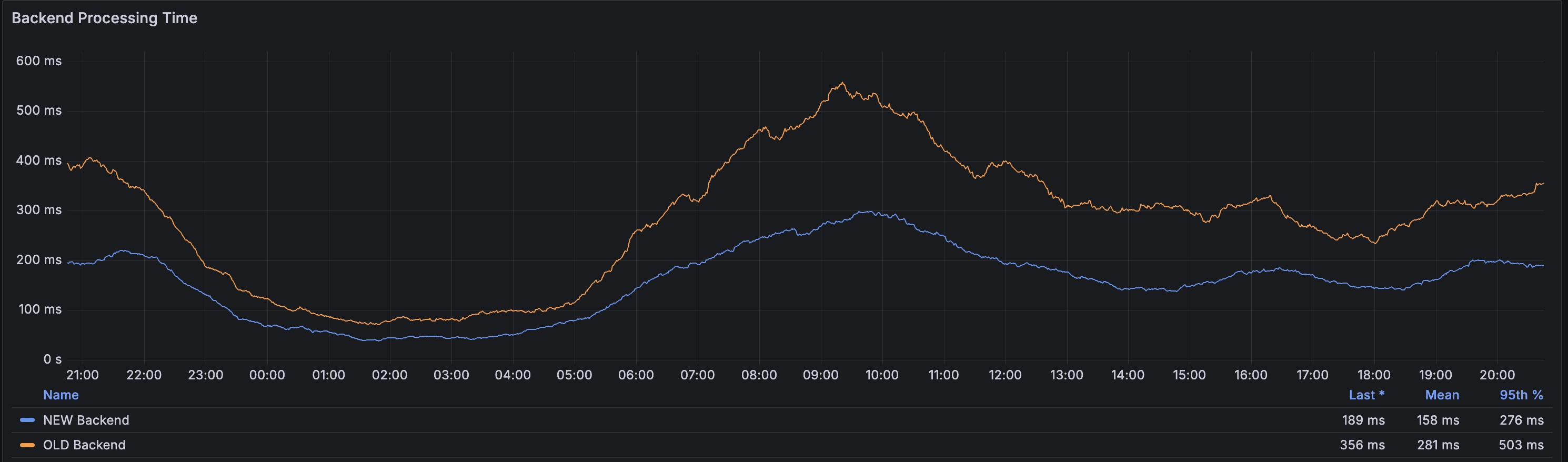
This improvement means that the time to first byte will be significantly faster for images that are not cached, which is crucial for first-time image optimizations.
Our caching systems continue to maintain an average cache-hit ratio of 99.3% throughout the day, meaning only 0.7% of all image requests result in a MISS. These 0.7% of requests benefit from this change.
About the Author
Lucas Rolff
Hosting Guru & FounderLucas is the founder and technical lead at PerfGrid, with over 15 years of experience in web hosting, performance optimization, and server infrastructure. He specializes in building high-performance hosting solutions and dealing with high-traffic websites.
Areas of expertise include: Web Hosting, Performance Optimization, Image Optimization, Hardware benchmarking

