






Udgivet: af Lucas Rolff
Pulse Uge 13: AVIF Effort Indstillinger og Photon Optimizer flytning
Test af AVIF effort indstillinger
I løbet af et par uger har vi leget med forskellige indstillinger for "CPU effort" altså »CPU-indsats«, når det drejer sig om at optimere AVIF-billeder som en del af Photon Optimizer.
AVIF har en såkaldt »CPU-indsats«, når man forsøger at komprimere billeder, indsatsen er en værdi mellem 0 og 9, og den fortæller egentligt AVIF-værktøjet, hvor meget tid den skal forsøge at bruge på at få en bedre komprimering af det givne billede i AVIF, da det at bruge mere tid kan resultere i større besparelser.
Det er dog vigtigt at bemærke, at hvis man nogle gange lægger for mange kræfter i det, vil det næsten ikke give noget udbytte, så det handler om at finde den rette balance.
I dette tilfælde er indsats 0 den langsomste (mest indsats), og 9 er den hurtigste (mindst indsats) - i nogen tid har vi valgt en indsats på 8, fordi den producerer lidt mindre billeder sammenlignet med WebP, mens den stadig er relativt hurtig.
Vi ville gerne se med forskellige indsatsindstillinger, hvordan det påvirker ikke kun hastigheden for at konvertere billeder til AVIF når vi ikke får et HIT fra vores Varnish-cache, men også naturligvis, om vi har nogen faktiske forbedringer med hensyn til filstørrelsen.
Det, vi ret hurtigt fandt ud af ved f.eks. at skifte CPU-indsats fra 8 til 7 (og dermed lægge lidt flere kræfter i det), var en stigning på 30% i vores 95. percentil af behandlingstiden for billedoptimering, hvilket er en væsentlig stigning. Vi opnåede dog kun omkring 1,4% i yderligere besparelser for billederne, baseret på ca. 550.000 unikke billeder, der går gennem platformen.
Mens nogle billeder naturligvis kan have en hel del flere besparelser, når man bruger flere kræfter på det, giver det simpelthen ikke mening at forsøge at øge CPU-indsatsen, når man ser på det samlede datasæt, vi har til rådighed.
Efterhånden som vi ser flere og flere billeder passere gennem vores Photon Optimizer-tjeneste, vil vi fortsætte med at udføre disse tests fra tid til anden, da typen af billeder generelt kan ændre sig med tiden.
Vi arbejder dog stadig på yderligere metoder, der forsøger at presse yderligere besparelser ud af både WebP- og AVIF-formaterne for at opnå endnu bedre besparelser for slutbrugerne.
Bemærk: I nogle tilfælde er indsatsen vendt om, så 0 er hurtigst og 9 er langsomst, dette er f.eks. tilfældet for værktøjer som Sharp
Flytning af Photon Optimizer-backend
Da vi alligevel har arbejdet på Photon Optimizer-tjenesten i de seneste uger, besluttede vi også at se på optimeringen af den underliggende hardware.
Oprindeligt, da tjenesten blev bygget, var den afhængig af Apache Traffic Server til at cachelagre nogle få steder, for at holde det relativt enkelt, ville Apache Traffic Server tale med en load balancer-IP, som ville have nogle Photon Optimizer workers bag sig.
Disse servere var af typen Hetzner Cloud CPX, som er såkaldte "delte" AMD-instanser.
Men på grund af en relativt ny ændring, hvor vi omlagde vores cache-bokse til at bruge en blanding af Varnish og haproxy, betyder det også, at vi pludselig kunne flytte yderligere failover-logik til hver enkelt cache-boks ved at lade haproxy overvåge flere upstreams/servere samt give dem forskellige prioriteter afhængigt af placeringen og ressourcernes størrelse. Som et resultat af dette har det gjort det muligt for os effektivt at bevæge os væk fra at kræve miljøer der er i et load balanced opsætning, men vi kan i stedet lave flere servere på tværs af flere udbydere i flere lande, hvis vi vil.
Så vi begyndte at teste forskellige hardwarekonfigurationer, primært for at teste, hvordan det gik med at konvertere et ret stort png-billede til AVIF, da AVIF er noget mere ressourcekrævende end WebP-konvertering.
Vi kiggede på, hvilken hardware vi havde til rådighed, og udførte nogle relativt grundlæggende benchmarks ved at affyre to samtidige forespørgsler hele tiden i en længere periode for at få et godt gennemsnit.
Det konverterede billede blev gemt lokalt på hver enkelt server i ramdisk for helt at fjerne netværks- og disk-IO som en faktor i vores benchmark, og testene blev udført over det lokale netværk for at sikre minimal latenstid mellem selve testklienten og workeren.
Som du kan se på listen nedenfor, varierer hastigheden af vores testbillede en hel del afhængigt af den underliggende hardware, og vi udførte en test mellem en dedikeret server med en AMD Ryzen 7900 og en VM-udbyder, der tilbyder VM'er med AMD Ryzen 7900, da vi ville se, hvor stor en indvirkning virtualisering havde på hastigheden, og selvom der er nogle besparelser at hente i de dedikerede løsninger, koster det naturligvis også betydeligt mere.
Det er værd at bemærke, at den Genoa-baserede VM var placeret på en hypervisor, som har en del belastning, og det er et kendt scenario på Genoa'er med højt antal kerner, at ydelsen vil lide, når du begynder at overskride de knap 50% CPU-belastning, det skyldes simpelthen begrænsninger i forhold til strømforbrug i CPU'en.
Dedicated AMD Ryzen 7900: Time per request: 411.743 [ms] (mean) VM based on AMD Ryzen 7900 (Borrowed from our friends at SpeedyPage): Time per request: 488.043 [ms] (mean) VM based on AMD Ryzen 7950X (Borrowed from our friends at SpeedyPage): Time per request: 490.261 [ms] (mean) VM based on AMD Genoa: Time per request: 734.398 [ms] (mean) Hetzner (CPX): Time per request: 835.570 [ms] (mean) VM based on AMD EPYC 7402: Time per request: 1057.406 [ms] (mean) Dedicated Intel Xeon 2698v4: Time per request: 1113.757 [ms] (mean) OVH VPS (EPYC, unknown generation): Time per request: 1172.953 [ms] (mean) Leaseweb VPS (EPYC, 7003 series): Time per request: 1352.599 [ms] (mean)
Vi fandt ud af, at AMD Ryzens generelt er en god spiller til tjenester som denne på grund af deres høje clockhastighed og gode IPC (instruktioner pr. clock).
Den 15. marts endte vi med at skifte til en Ryzen 7900-baseret backend på grund af de flotte tal fra vores benchmarks.
Baseret på den uges data, vi har til rådighed med hensyn til behandlingstider, kan vi se, at det er lykkedes os at reducere behandlingstiden for den 95. percentil med 45% ved at skifte backend-serverne ud.
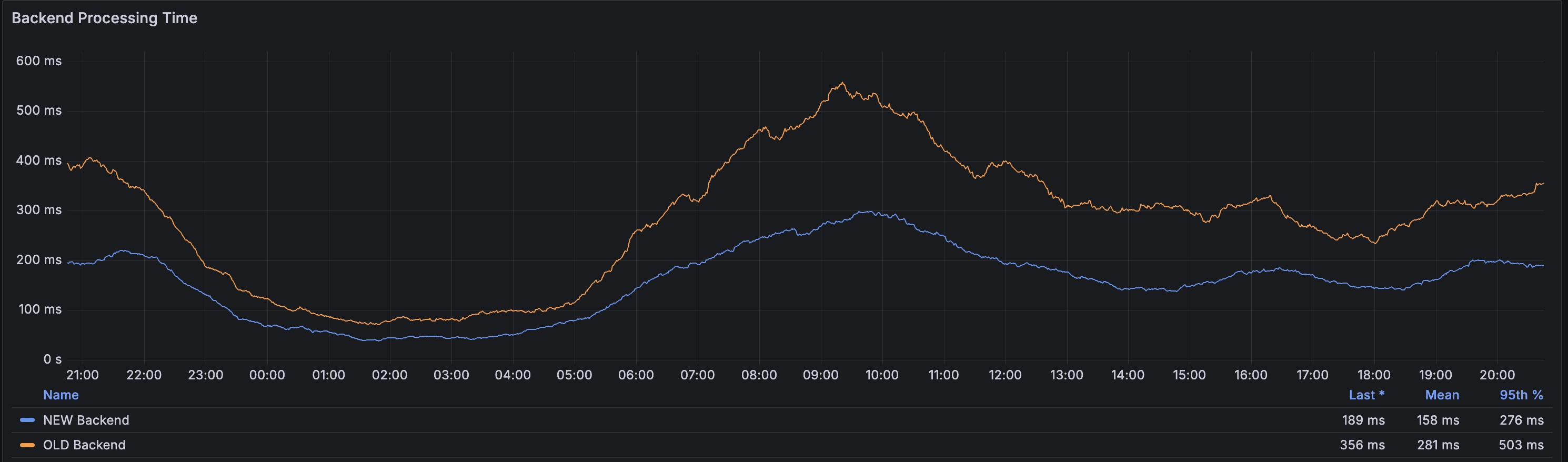
Det betyder, at for billeder, der ikke er cachelagret, vil tiden til første byte være betydeligt hurtigere, hvilket er vigtigt for førstegangsoptimeringer af billeder.
Vores cachesystemer formår stadig at opretholde en gennemsnitlig cache-hit ratio på 99,3% i løbet af dagen, så det er kun 0,7% af alle billedforespørgsler, der betragtes som MISS, og det er de 0,7%, der får gavn af denne ændring.
About the Author
Lucas Rolff
Hosting Guru & FounderLucas is the founder and technical lead at PerfGrid, with over 15 years of experience in web hosting, performance optimization, and server infrastructure. He specializes in building high-performance hosting solutions and dealing with high-traffic websites.
Areas of expertise include: Web Hosting, Performance Optimization, Image Optimization, Hardware benchmarking

